In the world of programming and data analysis, the Levenshtein distance plays a pivotal role in measuring how similar or different two strings are. This concept, also known as edit distance, quantifies the minimum number of single-character edits required to change one word into another. Python, with its rich ecosystem of libraries, makes it easy for developers to implement this algorithm for various applications, such as spell checking, DNA sequencing, and natural language processing.
When it comes to string comparison, the Levenshtein distance is a powerful tool that can help in identifying similarities and differences in textual data. By understanding how to utilize the levenshtein.distance function in Python, you can enhance your data manipulation skills and make your applications more efficient. In this article, we will delve into the essence of Levenshtein distance, its applications, and how to implement it using Python.
Whether you are a novice programmer or an experienced developer, grasping the intricacies of the Levenshtein distance can significantly improve your ability to work with strings. So, let’s embark on this journey to explore the levenshtein.distance function in Python and see how it can be applied in real-world scenarios.
What is Levenshtein Distance?
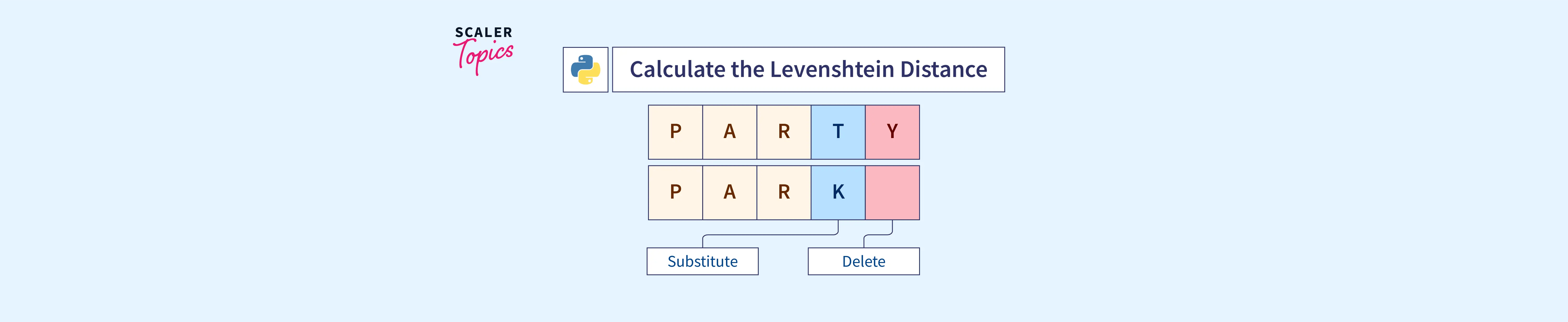
The Levenshtein distance measures the difference between two sequences. It is defined as the minimum number of single-character edits (insertions, deletions, or substitutions) required to transform one string into another. For instance, transforming "kitten" into "sitting" requires three edits: substituting 'k' with 's', replacing 'e' with 'i', and adding 'g' at the end.
How Does Levenshtein Distance Work in Python?
In Python, the Levenshtein distance can be calculated using various libraries, including `Levenshtein`, `difflib`, and custom implementations. The most straightforward way is to use the `python-Levenshtein` library, which provides a fast and efficient way to compute the distance.
What Libraries Can Be Used to Calculate Levenshtein Distance in Python?
- python-Levenshtein: A popular library specifically designed for calculating Levenshtein distance.
- difflib: A built-in Python module that provides tools for comparing sequences, including a method for calculating similarity ratios.
- fuzzywuzzy: A library that uses Levenshtein distance for fuzzy string matching.
How to Install the Python-Levenshtein Library?
To use the `python-Levenshtein` library, you need to install it via pip. Here’s how you can do it:
- Open your command line or terminal.
- Type the following command and hit Enter:
pip install python-Levenshtein
How to Use Levenshtein Distance in Python?
Once you have installed the library, you can easily compute the Levenshtein distance between two strings using the following code:
import Levenshtein string1 ="kitten" string2 ="sitting" distance = Levenshtein.distance(string1, string2) print(f"The Levenshtein distance between '{string1}' and '{string2}' is {distance}.")What Are the Applications of Levenshtein Distance?
The Levenshtein distance has a wide range of applications across various fields. Some of the most common uses include:
- **Spell Checking:** Identifying misspelled words by comparing them with a dictionary of correctly spelled words.
- **Natural Language Processing:** Analyzing text data to improve understanding and processing of human language.
- **DNA Sequencing:** Comparing genetic sequences to identify similarities and variations.
- **Plagiarism Detection:** Assessing the similarity between documents to identify potential plagiarism.
How to Improve Performance When Calculating Levenshtein Distance?
When working with large datasets or extensive strings, calculating the Levenshtein distance can become computationally expensive. Here are some strategies to improve performance:
- Use Efficient Libraries: Libraries like `python-Levenshtein` are optimized for performance.
- Parallel Processing: Divide the workload among multiple processors to speed up computation.
- Limit String Length: Pre-filter strings based on length to avoid unnecessary calculations.
What Are the Limitations of Levenshtein Distance?
While the Levenshtein distance is a powerful tool, it does have limitations:
- Character-Based Comparison: It does not account for the context or meaning of words.
- Case Sensitivity: The algorithm is case-sensitive, which may not be desirable in all applications.
- Performance on Large Data Sets: It can become slow with very large strings or extensive datasets.
Conclusion: Mastering Levenshtein Distance in Python
In conclusion, understanding the levenshtein.distance function in Python opens up a world of possibilities for text analysis and manipulation. By leveraging this powerful algorithm, developers can enhance their applications, improve data quality, and provide better user experiences. Whether you are developing a spell checker, analyzing DNA sequences, or creating a plagiarism detection tool, the Levenshtein distance is an essential concept to master in your programming toolkit.
Article Recommendations
- Lydian Mixolydian
- Price Tag Details
- Cars With Great Audio Systems
- Eau De Cologne Et Eau De Toilette
- Zhang Xueying
- Margot Robbie Weight Gain
- Gta Iv Script Hook
- Gen Tullos
- How To Turn Off Volte
- Goldman Sachs Pwm Associate Salary