In the world of data management, ensuring the integrity and accuracy of your database is paramount. One common issue that database administrators face is the presence of duplicate records. These duplicates can lead to incorrect data analysis, skewed reporting, and ultimately, poor decision-making. Therefore, knowing how to find duplicate records in SQL is an essential skill for anyone working with databases. Duplicate entries can occur for various reasons, such as data entry errors, import errors, or system migrations. Identifying and handling these duplicates is not just about cleaning up your database; it's about maintaining the reliability of your data for future operations.
Understanding how to find duplicate records in SQL involves learning various SQL queries and techniques. This guide will provide you with insights into the methods and best practices to efficiently detect and manage duplicate records in your database. Whether you're a beginner or an experienced SQL user, mastering this skill will enhance your data management capabilities and contribute to better data integrity.
Throughout this article, we will explore different SQL queries and approaches to identify duplicates, as well as strategies for handling them. By the end of this guide, you will have a solid grasp of how to find duplicate records in SQL and the various techniques available to manage them effectively.
What are Duplicate Records in SQL?
Duplicate records refer to multiple entries in a database table that contain the same values in one or more columns. These records can distort the accuracy of data retrieval and reporting, leading to unreliable insights. Consequently, it is crucial to identify and manage these duplicates efficiently.
Why is it Important to Find Duplicate Records in SQL?
Identifying and handling duplicate records is vital for several reasons:
- Data Integrity: Duplicates can compromise the integrity of your database.
- Accurate Reporting: Duplicate records can lead to misleading reports and analyses.
- Improved Performance: Removing duplicates can improve database performance and reduce storage costs.
- Enhanced User Experience: Ensuring data accuracy enhances user experience and trust.
How to Find Duplicate Records in SQL?
Finding duplicate records in SQL involves using specific queries to identify entries with identical values. Here are several approaches you can use:
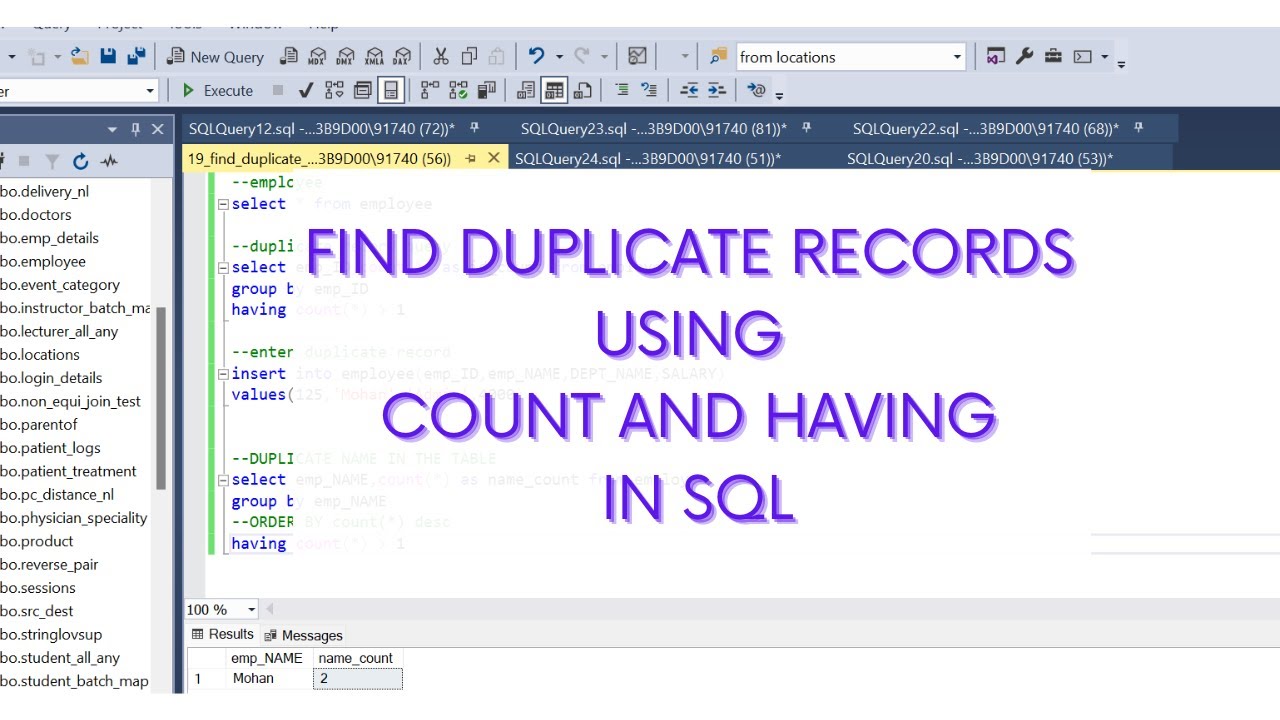
Using GROUP BY and HAVING Clauses
The most common method for finding duplicates is using the GROUP BY clause in combination with the HAVING clause. This approach allows you to group records by specific columns and filter out those with counts greater than one.
SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name HAVING COUNT(*) > 1;In this query, replace column_name with the specific column you want to check for duplicates, and table_name with the name of your table.
Example of Using GROUP BY
Consider a table named employees with a column named email. To find duplicate email addresses, you would use the following query:
SELECT email, COUNT(*) FROM employees GROUP BY email HAVING COUNT(*) > 1;Can You Use DISTINCT to Find Duplicates?
The DISTINCT keyword is often used to eliminate duplicate values from a result set. However, it does not directly help in finding duplicates. Instead, you can use DISTINCT in conjunction with other methods to compare counts or identify unique records.
How to Find Duplicate Records Using CTEs?
Common Table Expressions (CTEs) can also be employed to find duplicates. This approach can enhance readability and simplify complex queries.
WITH DuplicateRecords AS ( SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name HAVING COUNT(*) > 1 ) SELECT * FROM DuplicateRecords;This CTE will yield the same results as the previous GROUP BY query but in a more structured manner.
How to Identify Duplicate Records in Multiple Columns?
If you need to find duplicates based on multiple columns, you can adjust the GROUP BY clause accordingly. For example:
SELECT column1, column2, COUNT(*) FROM table_name GROUP BY column1, column2 HAVING COUNT(*) > 1;This will help you identify records that are duplicates based on the combination of values in column1 and column2.
What are the Best Practices for Managing Duplicate Records?
Once you’ve identified duplicate records, it's essential to manage them effectively. Here are some best practices:
- Data Cleaning: Regularly review and clean your data to prevent duplicates.
- Implement Constraints: Use unique constraints to prevent duplicate entries from being added in the first place.
- Data Validation: Implement data validation rules during data entry to minimize errors.
- Backup Data: Always backup your data before making bulk deletions or modifications.
Conclusion: How to Find Duplicate Records in SQL?
In summary, knowing how to find duplicate records in SQL is crucial for maintaining data integrity and ensuring accurate reporting. By using various SQL techniques like GROUP BY, HAVING clauses, CTEs, and understanding how to check multiple columns, you can efficiently identify and manage duplicates in your database. Following best practices for data management will further enhance your database's reliability and performance. Embrace these skills, and you will enhance your SQL proficiency and contribute to better data management practices.
Article Recommendations
- Kobe Thai
- Ui For Apache Kafka Value Filter
- Encroachment Easement
- Old Dollar Shave Club Handle
- Emo In Thong
- Water Dam For House
- Fernando Godoy
- Semi Gloss Polyurethane
- Cleaning Kenmore Dishwasher
- Goldman Sachs Pwm Associate Salary